HCA-776
The LLM optimized carbon capture enzymes have officially been produced and validated. The best designs were 170% more active and 25% more stable across extreme pH (Tm +8.5 C).
A few months ago, I RLed an LLM towards a rosetta energy function objective to optimize protein sequences. Pro-1 appeared to have strong benchmark performance, outperforming all of the frontier models on a custom protein stability eval. Initial wet lab validations on FGF-1 (a naturally unstable growth factor) showed promising results, with gains in melting temperature of up to 23 degrees celsius. With these successes, it was time to test the model on a true application.
Carbonic anhydrases have been heavily researched for carbon capture applications due to their remarkable CO₂ conversion efficiency. Among these, HCA II is an exceptionally efficient candidate, speeding up the conversion of carbon dioxide to bicarbonate by a factor of 10^7.
However, practical deployments of carbonic anhydrases are particularly challenging as variants must retain high stability and activity in everchanging field conditions. In many open air applications, such as enhanced rock weathering, enzymes need to remain functional in both the acidic conditions found in agricultural soils, as well as the basic conditions that arise as the basalt weathers and releases alkaline minerals.
Additionally, enzyme optimization is particularly difficult. In contrast with small peptides or binders, enzymes are highly dynamic molecules and rely heavily on conformational changes to perform their function. Even the most minor of mutations can disrupt dynamics and active site geometry, making it difficult to improve stability without compromising activity.
Engineering a highly active and stable carbonic anhydrase variant is no easy feat. But improving carbon capture efficiency by orders of magnitude feels like a worthy first target for Pro-1.
Methods
5 sequences from the original Pro-1 generations (4 conservative, 1 creative) were selected for wet lab validation. Sequences with more conservative modifications were selected due to their higher likelihood of successful expression during the FGF-1 validation.
I also generated 4 sequences with sonnet 4 + specific tools for enzyme optimization. Examples of tools include pymol catalytic site examiner, literature search, notebook reads/writes, etc. The motivation here was to determine if sonnet 4, a generalist model with tools, could achieve similar results with a smaller model specifically posttrained on the task of protein optimization. In other words, could an industry veteran design better sequences than an intelligent individual with tools?

The agent would run in a loop for hours at a time, keeping a log of the best modifications it discovered in the process that it could read and write to as it decided. Each of the best agent results employed different approaches, with some reasoning from first principles about the structure and others searching the literature for related results, drawing inspiration from modifications proven to work for other enzymes.
Lab Results
We ran 11 sequences in total (1 WT, 4 Pro-1, 4 agent, 1 deep research) on a colorimetry assay as a proxy for activity, a sypro orange thermal shift assay for baseline thermal stability, and then ran the thermal shift at various pH's to test for stability in highly acidic and basic conditions. Slope of the nitrophenol line and sypro orange fluorescence were used to determine activity and melting temperatures respectively.
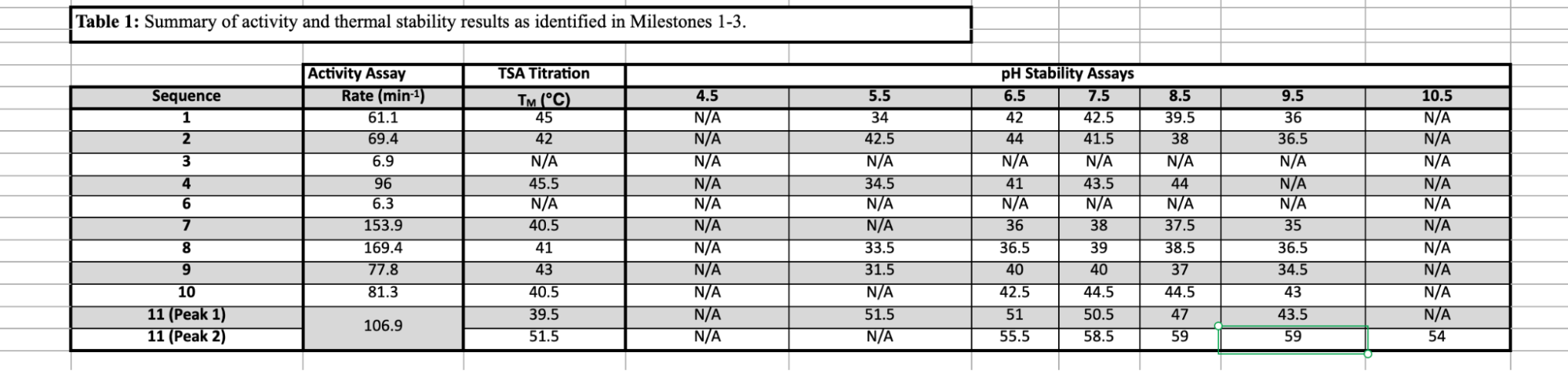
Nearly all of the sequences (8/11) expressed well and showed increased activity. 4 of these showed increased stability at pH of 5.5 or 9.5. None of the variants proposed had been previously discovered or characterized.
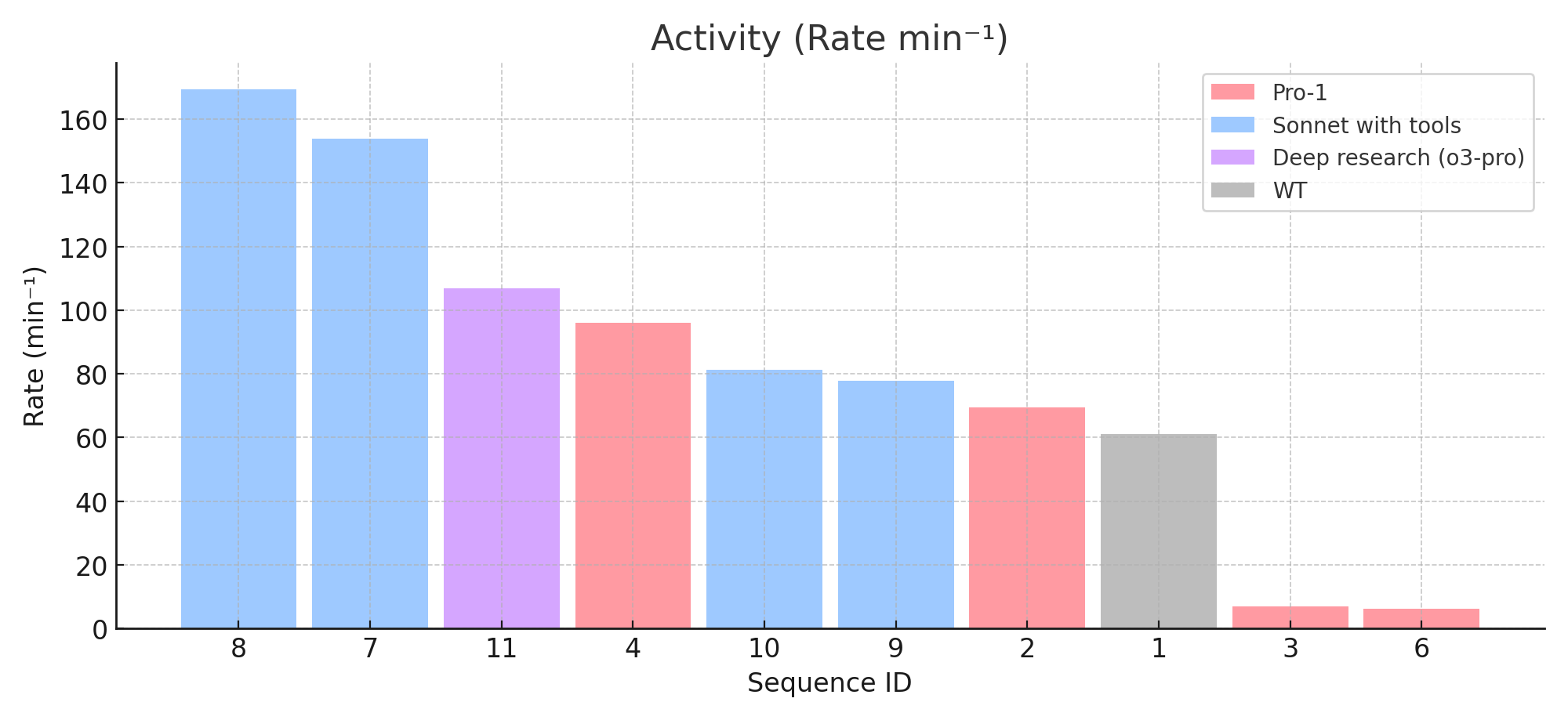
The best sequence across conditions was produced by the "creativity tuned" Pro-1 model. Claude with tools produced significantly more active enzymes with elevated stability in highly basic environments.
Best activity: 169.4 min-1 (+177%) (sonnet)
Best at ph 5.5: Tm 42.5 (+8.5 degrees C) (pro-1)
Best at pH 9.5: 43 (+8 deg C) (sonnet)
Note that many of the sequences are particularly good for a certain application (good in high vs low pH, higher temp, higher activity). However, sequences 2, 10, and 11 appear to be useful across a number of conditions.
Also worth noting the discrepancy between TSA titration Tm and pH stability Tm. Not certain why these are so different despite running the same sypro orange assay, but given that the pH stability assays more accurately reflect deployment conditions and have significantly more samples, I am inclined to attribute the difference to noise.
Successful Strategies
I was quite surprised when the "creative" strategy not only produced a functional sequence, but was also the most stable across all conditions with elevated activity compared to WT. The focus of this strategy was adding a tag from the literature that worked for an alpha carbonic anhydrase from Thermovibrio ammonificans which has been shown to improve solubility and expression. Adapting this tag to hCA II required selecting where on the N-terminus it would fall, which residues to replace (if any), and what subsequences from the tag should be added.

Edit: The NEXT tag the model claimed to be translating from literature is significantly different from the actual NEXT tag in literature! The NEXT tag in literature is 53 aa and appears to be completely different. The model likely took the concept of the NEXT tag and hallucinated a variation of that for hCA II. And it somehow worked? Either the model built an incredibly strong intuition of stability during the SFT/RL or it got lucky.
Claude identified that hCA II was an alpha carbonic anhydrase and was primarily composed of beta sheets. From this, it decided to search the literature for beta barrel insertions in known thermozymes. It then found some sources on mutations that enhance beta barrel core packing and hydrophobic interactions, and selected relevant mutations such as L78I and I208V. The reasoning traces from the agent are unfortunately less interesting and do not include many thinking tokens between tool calls. Will be curious to see how this has changed with the newer models in the next phase.

Bonus o3 Sequence
Out of curiosity, I also gave deep research (powered by o3-pro) a chance to provide some candidates for synthesis. The reasoning itself was significantly stronger, and the model collected a diverse set of relevant sources across the literature to inform its mutations.
Doubtful of the suggested modifications, I checked rosetta scores, RMSD, and even visually examined the structure of the o3 variant. All evidence indicated that the sequence was highly unstable. However, after some back and forth, the model remained remarkably confident in its proposed mutations, criticized my methods, and persuaded me to include the sequence in the validation.
The results were mixed. On the one hand, the Tm curves at pH 5.5 and 9.5 are reasonably smooth and the activity curve at neutral pH indicates that the enzyme is functional. However, the presence of multiple peaks in the other melting curves raises questions about true functionality. The most likely explanation for this is that there is a separate region of the protein that unfolds at lower temperature before the main unfolding event happens at higher temperature. Whether or not the protein remains functional after this first event is unclear.
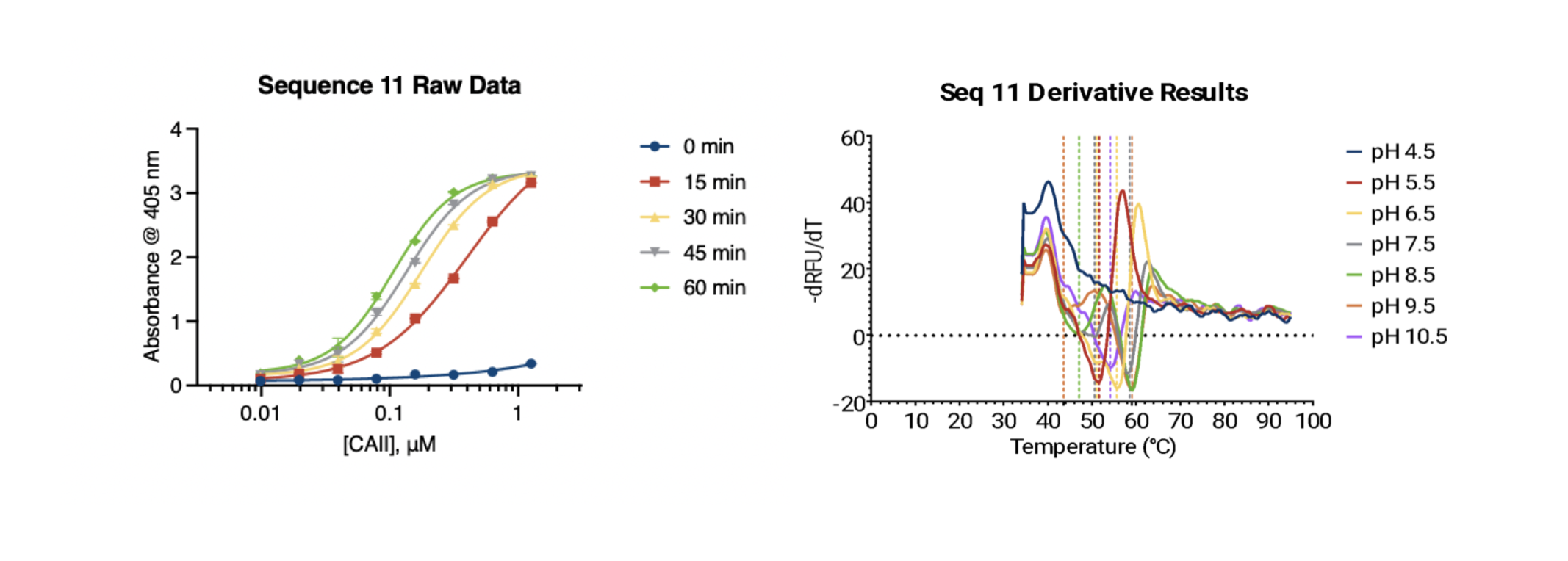
If the results are valid, the deep research variant would be the best carbonic anhydrase by far. However, it's difficult to draw any meaningful conclusions given the presence of atypical melting curves. We'll include a version of this in the next phase for kicks.
Limitations
- TSA thermal stability did not seem to increase significantly for most of the designs, despite increasing for the pH assay, discussed above
- If Pro-1 hallucinates a mutation or a residue that does not exist, the sequence applier LLM interprets the intent of the model and then makes a "best guess" at what pro-1 intended. This introduces some variance and is obviously not ideal, but for now seems to work well enough.
- With the agent, the lack of interesting reasoning traces makes it feel like the successful sequences occurred by chance. However, because the success rate was high and the tool inputs/outputs seem to be grounded in some biological intuition, this seems less likely but possible.
- Bizarre activity increases from the agent despite no explicit instruction to optimize activity. It's possible that since most of the strategies from the agent modify inner residues, these would affect catalytic activity. And then because the agent was drawing inspiration from literature, it may have inadvertently found mutations that increase activity in other enzymes? Unclear.
Next Steps
There is still a substantial amount of work to be done before the enzymes can be productionized. Current priority is translation to a deployment environment. While these lab results are promising, a significant amount of optimization is still required to ensure the enzymes are effective (ie. immobilization, long term stability, retained activity, etc). In talks with a large scale deployment partner, more on this soon.
For now, this is a significant milestone in AI for science. Efficiency of carbon capture methods will be one of the most important objectives to hill climb over the coming decades and LLM's seem to be well equipped for the intelligence and creativity required by the task. Today, these models can create more efficient carbonic anhydrases, but tomorrow they may design a completely novel material or process orders of magnitude better than the enzymes produced above. As the models continue to defy the odds, the only reasonable conclusion remaining is that there is no upper bound on the potential of this technology.
Special thanks to Alexis Ohanian, Lissie Garvin, and the 776 Foundation for helping to sponsor the synthesis. Also big thanks to Julian Englert and the Adaptyv Bio team for sponsoring the initial FGF-1 validations of Pro-1.